Subtask A: Entity recognition
Given a list of eHealth documents written in Spanish, the goal of this subtask is to identify all the entities per document and their types. These entities are all the relevant terms (single word or multiple words) that represent semantically important elements in a sentence. The following figure shows the relevant entities that appear in a set of example sentences.
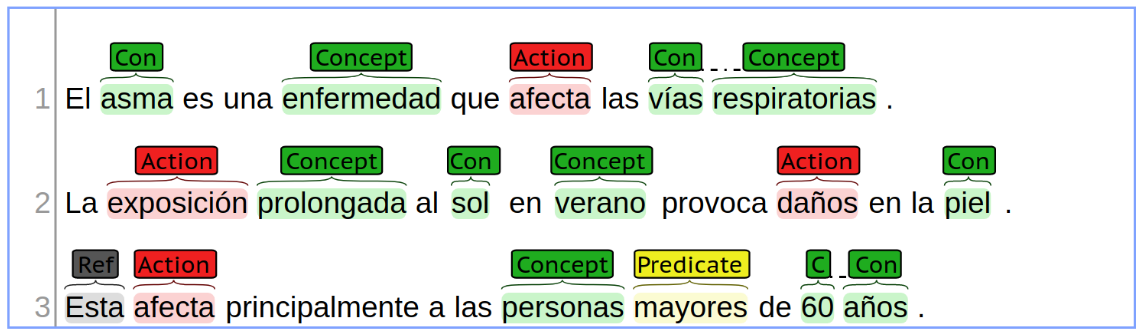
Note that some entities (“vías respiratorias” and “60 años”) span more than one word. Entities will always consist of one or more complete words (i.e., not a prefix or a suffix of a word), and will never include any surrounding punctuation symbols, parenthesis, etc. There are four types for entities:
- Concept: indentifies a relevant term, concept, idea, in the knowledge domain of the sentence.
- Action: indentifies a process or modification of other entities. It can be indicated by a verb or verbal construction, such as “afecta” (affects), but also by nouns, such as “exposición” (exposition), where it denotes the act of being exposed to the Sun, and “daños” (damages), where it denotes the act of damaging the skin. It can also be used to indicate non-verbal functional relations, such as “padre” (parent), etc.
- Predicate: identifies a function or filter of another set of elements, which has a semantic label in the text, such as “mayores” (older), and is applied to an entity, such as “personas” (people) with some additional arguments such as “60 años” (60 years).
- Reference: identifies a textual element that refers to an entity –of the same sentence or of different one–, which can be indicated by textual clues such as “esta”, “aquel”, etc.
Subtask B: Relation extraction
Subtask B continues from the output of Subtask A, by linking the entities detected and labelled in the input document. The purpose of this subtask is to recognize all relevant semantic relationships between the entities recognized. Eight of the thirteen semantic relations defined for this challenge can be identified in the following example:
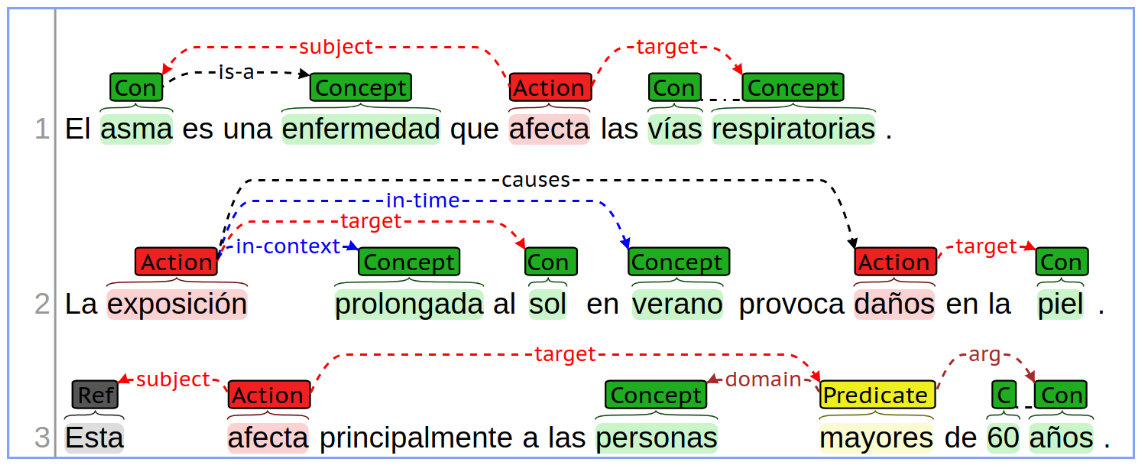
The semantic relations are divided in different categories:
General relations (6): general-purpose relations between two concepts (it involves Concept, Action, Predicate, and Reference) that have a specific semantic. When any of these relations applies, it is preferred over a domain relation –tagging a key phrase as a link between two information units–, since their semantic is independent of any textual label:
- is-a: indicates that one entity is a subtype, instance, or member of the class identified by the other.
- same-as: indicates that two entities are semantically the same.
- has-property: indicates that one entity has a given property or characteristic.
- part-of: indicates that an entity is a constituent part of another.
- causes: indicates that one entity provoques the existence or occurrence of another.
- entails: indicates that the existence of one entity implies the existence or occurrence of another.
Contextual relations (3): allow to refine an entity (it involves Concept, Action, Predicate, and Reference) by attaching modifiers. These are:
- in-time: to indicate that something exists, occurs or is confined to a time-frame, such as in “exposición” in-time “verano”.
- in-place: to indicate that something exists, occurs or is confined to a place or location.
- in-context: to indicate a general context in which something happens, like a mode, manner, or state, such as “exposición” in-context “prolongada”.
Action roles (2): indicate which role play the entities related to an Action:
- subject: indicates who performs the action, such as in “[el] asma afecta […]”.
- target: indicates who receives the effect of the action, such as in “[…] afecta [las] vías respiratorias”. Actions can have several subjects and targets, in which case the semantic interpreted is that the union of the subjects performs the action over each of the targets.
Predicate roles (2): indicate which role play the entities related to a Predicate:
- domain: indicates the main entity on which the predicate applies.
- arg: indicates an additional entity that specifies a value for the predicate to make sense. The exact semantic of this argument depends on the semantic of the predicate label, such as in “mayores [de] 60 años”, where the predicate label “mayores” indicates that “60 años” is a quantity, that restricts the minimum age for the predicate to be true.
Input and output format
Input files in the eHealth-KD 2021 are plain text files in UTF-8 format with one sentence per line. Sentences have not been preprocesed in any sense.
The output is always one file in BRAT standoff format, where each line represents either an entity or a relation. All details about the required format are available in the link above. We provide Python scripts to read and write this format in the repository of the eHealth-KD 2021 Challenge. More details in the Resources section.
An example output file for the annotation represented in the previous images is provided below:
The order in which the entities and relations appear in the output file is irrelevant. It is only important to be consistent with respect to identifiers. Each entity has a unique identifier that is used in relation annotations to reference it. Your output file can have different identifiers than the gold output, and the evaluation scripts will be able to correctly find matching annotations.
For example, if in your output the entity “asma” has ID T3 instead of T1 as in the previous example, and there appears a relation annotation R1 is-a Arg1:T3 Arg2:T2, this will be correctly matched with the corresponding gold annotation. Relation IDs are necesary for the BRAT format to be correctly parsed, but are irrelevant with respect to the evaluation of the task. Feel free to simply use autoincremental identifiers, or use the provided Python scripts, which already take care of all these details.
Challenge Scenarios
The eHealth-KD 2021 Challenge proposes 4 evaluation scenarios:
Main Evaluation (Scenario 1)
This scenario evaluates all of the subtasks together as a pipeline. The input consists only of a plain text, and the expected output is a BRAT .ann file with all the corresponding entities and relations found.
The measures will be precision, recall and F1 as follows:
\[Rec_{AB} = \frac{C_A + C_B + \frac{1}{2} P_A}{C_A + I_A + C_B + P_A + M_A + M_B}\] \[Prec_{AB} = \frac{C_A + C_B + \frac{1}{2} P_A}{C_A + I_A + C_B + P_A + S_A + S_B}\] \[F_{1AB} = 2 \cdot \frac{Prec_{AB} \cdot Rec_{AB}}{Prec_{AB} + Rec_{AB}}\]F1 will determine the ranking of Scenario 1 and consequently of the eHealthKD challenge.
The exact definition of Correct, Missing, Spurious, Partial and Incorrect is presented in the following sections for each subtask.
Optional Subtask A (Scenario 2)
This scenario only evaluates Subtask A. The input is a plain text with several sentences and the output is a BRAT .ann file with only entity annotations in it (relation annotations are ignored if present).
To compute the scores we define correct, partial, missing, incorrect and spurious matches. The expected and actual output files do not need to agree on the ID for each entity, nor on their order. The evaluator matches are based on the start and end of text spans and the corresponding type. A brief description about the metrics follows:
- Correct matches are reported when a text in the dev file matches exactly with a corresponding text span in the gold file in START and END values, and also the entity type. Only one correct match per entry in the gold file can be matched. Hence, duplicated entries will count as Spurious.
- Incorrect matches are reported when START and END values match, but not the type.
- Partial matches are reported when two intervals [START, END] have a non-empty intersection, such as the case of “vías respiratorias” and “respiratorias” in the previous example (and matching LABEL). Notice that a partial phrase will only be matched against a single correct phrase. For example, “tipo de cáncer” could be a partial match for both “tipo” and “cáncer”, but it is only counted once as a partial match with the word “tipo”. The word “cancer” is counted then as Missing. This aims to discourage a few large text spans that cover most of the document from getting a very high score.
- Missing matches are those that appear in the gold file but not in the dev file.
- Spurious matches are those that appear in the dev file but not in the gold file.
From these definitions, we compute precision, recall, and a standard F1 measure as follows:
\[Rec_{A} = \frac{C_A + \frac{1}{2} P_A}{C_A + I_A + P_A + M_A}\] \[Prec_{A} = \frac{C_A + \frac{1}{2} P_A}{C_A + I_A + P_A + S_A}\] \[F_{1A} = 2 \cdot \frac{Prec_{A} \cdot Rec_{A}}{Prec_{A} + Rec_{A}}\]A higher precision means that the number of spurious identifications is smaller compared to the number of missing identifications, and a higher recall means the opposite. Partial matches are given half the score of correct matches, while missing and spurious identifications are given no score.
F1 will determine the ranking of Scenario 2.
Optional Subtask B (Scenario 3)
This scenario only evaluates Subtask B. The input is plain text and a corresponding .ann file with the correct entities annotated.
The expected output is a .ann file with both the entities and relations. Feel free to simply copy the entity annotations from the provided .ann file and append the relation annotations.
To compute the scores we define correct, missing, and spurious matches. The expected and actual output files do not need to agree on the ID for each relation (which is ignored) nor on their order. The evaluator matches are based on the start and end of text spans and the corresponding type. A brief description about the metrics follows:
- Correct: relationships that matched exactly to the gold file, including the type and the corresponding IDs for each of the participants.
- Missing: relationships that are in the gold file but not in the dev file, either because the type is wrong, or because one of the IDs didn’t match.
- Spurious: relationships that are in the dev file but not in the gold file, either because the type is wrong, or because one of the IDs didn’t match.
We define standard precision, recall and F1 metrics as follows:
\[Rec_{B} = \frac{C_B}{C_B + M_B}\] \[Prec_{B} = \frac{C_B}{C_B + S_B}\] \[F_{1B} = 2 \cdot \frac{Prec_{B} \cdot Rec_{B}}{Prec_{B} + Rec_{B}}\]F1 will determine the ranking of Scenario 3.
NOTE: The Scenario 1 is more complex than solving each optional scenario separately, since errors in subtask A will necessary translate to errors in subtask B. For this reason it is considered the main evaluation metric. Additionally, this scenario also provides the possibility for integrated end-to-end solutions that solve both subtask simultaneously.
Important: Note about negated concepts
The eHealth-KD 2021 corpus considers negated actions, which are manually annotated in the corresponding Brat files (which will be released after the challenge is completed). However, for competition purposes, we are not considering the annotation of negation as part of the challenge.
This means that, in the corpus, you will find sentences with negated concepts, such as: “No existe un tratamiento que restablezca la función ovárica normal.”. In this and similar sentences, we still expect that your system recognizes existe as Action and tratamiento as Target, as though if the negation did not exist.
If in doubt please contact the organizers at ehealth-kd@googlegroups.com.