IberLEF eHealth Knowledge Discovery Challenge 2021
🗨️ Follow @EHealthKD on Twitter for up-to-date information.
🏆 As of May 4th, 2021 the official results are available (read below)!
Natural Language Processing (NLP) methods are increasingly being used to mine knowledge from unstructured health texts. Recent advances in health text processing techniques are encouraging researchers and health domain experts to go beyond just reading the information included in published texts (e.g. academic manuscripts, clinical reports, etc.) and structured questionnaires, to discover new knowledge by mining health contents. This has allowed other perspectives to surface that were not previously available.
Over the years, many eHealth challenges have attempted to identify, classify, extract, and link knowledge, such as Semevals, CLEF campaigns, and others.
The eHealth-KD 2021 proposes modeling the human language in a scenario in which Spanish electronic health documents could be machine-readable from a semantic point of view. With this task, we expect to encourage the development of software technologies to automatically extract a large variety of knowledge from eHealth documents written in the Spanish Language.
Even though this challenge is oriented to the health domain, the structure of the knowledge to be extracted is general-purpose. The semantic structure proposed models four types of information units. Each one represents a specific semantic interpretation, and they make use of thirteen semantic relations among them. Furthermore, although the challenge will contain a majority of Spanish sentences in the health domain, it will also include a small selection of sentences from different domains and languages (i.e., English) to encourage cross-domain and multi-lingual approaches. Participants can opt-out of this additional requirement at evaluation time.
The following sections provide a detailed presentation of each unit and relation type. An example is provided in the following picture.
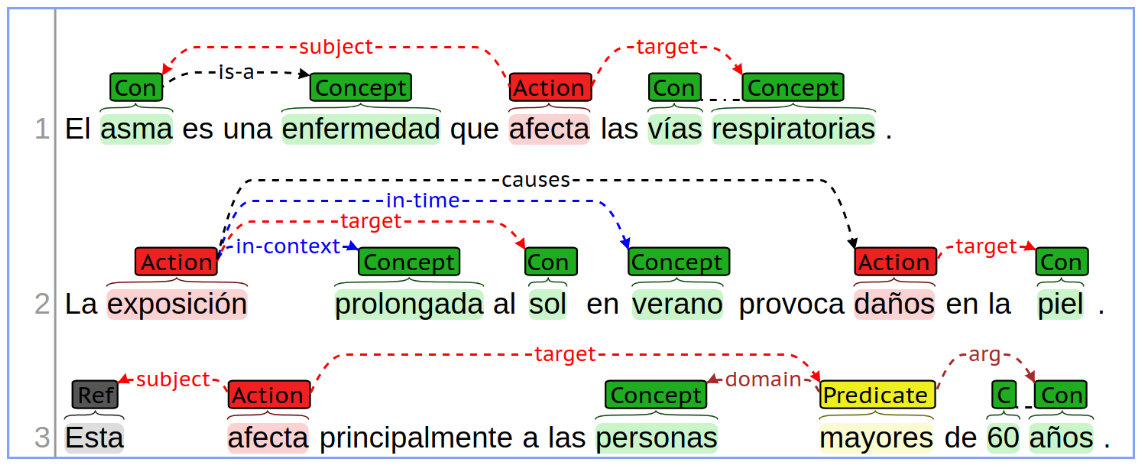
This challenge can be of interest to experts in the field of natural language processing, specifically for those working on automatic knowledge extraction and discovery. It is not a requirement to have expertise in health text processing for dealing with the eHealth-KD task, due to the general purpose of the semantic schema defined. Nevertheless, eHealth researchers could find interesting this challenge to evaluate their technologies that rely on health domain knowledge.
Programme
Online on September 21, 2021. Registration requiered at: CEDI
| From | To | Description | Bibtext | Video | Paper | |
|---|---|---|---|---|---|---|
| - | 12:30h | 14:00h | eHealth-KD 2021: eHealth Knowledge Discovery | |||
| - | 12:30h | 12:50h | Overview of the eHealth Knowledge Discovery Challenge at IberLEF 2021 Alejandro Piad-Morfis, Suilan Estevez-Velarde, Yoan Gutierrez, Yudivian Almeida-Cruz, Andrés Montoyo, Rafael Muñoz | @ | 🎥 | 📄 |
| - | 12:50h | 13:00h | Vicomtech at eHealth-KD Challenge 2021: Deep Learning Approaches to Model Health-related Text in Spanish. Aitor García-Pablos, Naiara Perez, and Montse Cuadros | @ | 🎥 | 📄 |
| - | 13:00h | 13:10h | PUCRJ-PUCPR-UFMG at eHealth-KD Challenge 2021: A Multilingual BERT-based System for Joint Entity Recognition and Relation Extraction. Lucas Pavanelli, Elisa Terumi Rubel Schneider, Yohan Bonescki Gumiel, Thiago Castro Ferreira, Lucas Ferro Antunes de Oliveira, João Vitor Andrioli de Souza, Giovanni Pazini Meneghel Paiva, Lucas Emanuel Silva e Oliveira, Claudia Maria Cabral Moro, Emerson Cabrera Paraiso, and Adriana Pagano | @ | 🎥 | 📄 |
| - | 13:10h | 13:20h | IXA at eHealth-KD Challenge 2021: Generic Sequence Labelling as Relation Extraction Approach. Edgar Andrés | @ | 🎥 | 📄 |
| - | 13:20h | 13:30h | Round of short presentations | |||
| - | JAD at eHealth-KD Challenge 2021: Simple Neural Network with BERT for Joint Classification of Key-Phrases and Relations. José Gabriel Navarro Comabella, Jorge Daniel Valle Diaz, Alberto Helguera Fleitas | @ | 🎥 | 📄 | ||
| - | UH-MMM at eHealth-KD Challenge 2021: Loraine Monteagudo-García, Amanda Marrero-Santos, Manuel Santiago Fernández-Arias, Hian Cañizares-Díaz | @ | 🎥 | 📄 | ||
| - | uhKD4 at eHealth-KD Challenge 2021: Deep Learning Approaches for Knowledge Discovery from Spanish Biomedical Documents: Dayany Alfaro-González, Dalianys Pérez-Perera, Gilberto González-Rodríguez, Antonio Jesús Otaño-Barrera, Rocío Cruz-Linares | @ | 🎥 | 📄 | ||
| - | Yunnan-1 at eHealth-KD Challenge 2021: Deep-Learning Methods for Entity Recognition in Medical Text: Maoqin Yang | @ | 🎥 | 📄 | ||
| - | Yunnan-Deep at eHealth-KD Challenge 2021: Deep Learning Model for Entity Recognition in Spanish Documents: Zhengyi Guan, Renyuan Liu | @ | 🎥 | 📄 | ||
| - | 13:30h | 14:00h | Discussion |
The overall IberLEF workshop program can be found at the following link.
🏆 Official results
The official results for Scenarios 1, 2, and 3 are presented next. You can download CSV) and JSON formats of these results.
⚠️ NOTE: Team names have been taken from Codalab user names. Please contact us to update the official names for the teams.
Only participants that submitted for each specific scenario are shown.
Scenario 1 (Main Evaluation)
| Team | F1 | Precision | Recall | Bibtex | Video | Paper | |
|---|---|---|---|---|---|---|---|
| 🥇 | Vicomtech | 0.53106 | 0.54075 | 0.53464 | @ | 🎥 | 📄 |
| 🥈 | PUCRJ-PUCPR-UFMG | 0.52835 | 0.56849 | 0.50276 | @ | 🎥 | 📄 |
| 🥉 | IXA | 0.49886 | 0.46457 | 0.53863 | @ | 🎥 | 📄 |
| uhKD4 | 0.42264 | 0.48529 | 0.37431 | @ | 🎥 | 📄 | |
| UH-MMM | 0.33865 | 0.29163 | 0.40374 | @ | 🎥 | 📄 | |
| Codestrange | 0.23201 | 0.33703 | 0.17689 | @ | |||
| baseline | 0.23201 | 0.33703 | 0.17689 | @ | |||
| JAD | 0.10949 | 0.23441 | 0.07143 | @ | 🎥 | 📄 |
Scenario 2 (Task A)
| Team | F1 | Precision | Recall | Bibtex | Video | Paper | |
|---|---|---|---|---|---|---|---|
| 🥇 | PUCRJ-PUCPR-UFMG | 0.70601 | 0.71491 | 0.69733 | |||
| 🥈 | Vicomtech | 0.68413 | 0.69987 | 0.74706 | |||
| 🥉 | IXA | 0.65333 | 0.61372 | 0.6984 | |||
| UH-MMM | 0.60769 | 0.54604 | 0.68503 | ||||
| uhKD4 | 0.52728 | 0.51751 | 0.53743 | ||||
| Yunnan-Deep | 0.33406 | 0.52036 | 0.24599 | @ | 🎥 | 📄 | |
| baseline | 0.30602 | 0.35034 | 0.27166 | ||||
| JAD | 0.2625 | 0.31579 | 0.2246 | ||||
| Yunnan-1 | 0.17322 | 0.27107 | 0.12727 | @ | 🎥 | 📄 | |
| Codestrange | 0.08019 | 0.415 | 0.04439 |
Scenario 3 (Task B)
| Team | F1 | Precision | Recall | |
|---|---|---|---|---|
| 🥇 | IXA | 0.4304 | 0.45357 | 0.40948 |
| 🥈 | Vicomtech | 0.37191 | 0.54186 | 0.28311 |
| 🥉 | uhKD4 | 0.31771 | 0.55623 | 0.22236 |
| PUCRJ-PUCPR-UFMG | 0.26324 | 0.36659 | 0.20535 | |
| UH-MMM | 0.05384 | 0.07727 | 0.04131 | |
| Codestrange | 0.03275 | 0.4375 | 0.01701 | |
| baseline | 0.03275 | 0.4375 | 0.01701 | |
| JAD | 0.00722 | 0.375 | 0.00365 |
Description of the Subtasks
To simplify the evaluation process, two subtasks are presented:
Submissions and evaluation
There are four evaluation scenarios:
- A main scenario covering both tasks
- An optional scenario evaluating subtask A
- An optional scenario evaluating subtask B
📝 Details about the submission format will be provided shortly.
Resources
All the data will be made available to participants in due time. This includes training, development and test data, as well as evaluation scripts and sample submissions. More details are provided here.
All the resources are available in the eHealth-KD corpora repository.
Submission
🏆 Go to the Official Server
The challenge will be graded on Codalab.org. Check out the submission instructions for more details. There is also an ongoing training competition already hosted where you can try your system on the training dataset and development, to get acquainted with the submission workflow before trying the official server.
Schedule
| Date | Event | Link |
|---|---|---|
| 08 Mar 2021 | 🏋️ Training data released | 💾 Training set 🔧 Utility scripts |
| 29 Mar 2021 | 🏃 Development data released | 💾 Develop set |
19 Apr 2021 |
⚗️ Evaluation period begins – test data released | 💾 Test set 🏆 Official server |
30 Apr 2021 |
🤯 Evaluation period ends – due by 23:59 GMT-12 (AoE) | |
03 May 2021 |
🏆 Results posted | |
16 May 2021 |
🗞️ System descriptions due – closes by 23:59 GMT-12 (AoE) | |
| 24 May 2021 | 📝 Papers reviews due | |
| 31 May 2021 | 💌 Authors notifications | |
| 14 Jun 2021 | 📸 Camera ready submissions due – closes by 23:59 GMT-12 (AoE) |
Publication instructions
📝 Official instructions and templates for the description paper will be provided shortly.
The Organization Committee of eHealth-KD encourages participants to submit a description paper of their systems. Submitted papers will be reviewed by a scientific committee, and only accepted papers will be published at CEUR. The proceedings of eHealth-KD will be jointly published with the proceedings of all tasks of IberLEF 2021. The submitted papers will be peer-reviewed by a Program Committee which is composed by all the participants and the Organization Committee.
- Articles must be written in English, five pages minimun.
- The document format can be Word or LaTeX, but the submission must be in PDF format.
- Please make sure to follow all the additional instructions provided in the template and respect the layout and formatting:
- Overleaf users can clone this project, which also contains some additional instructions specific to the eHealth-KD Challenge (PDF version here).
- Offline versions for LaTeX and DOCX are available from CEUR, but please make sure to read the official instructions in the previous link.
Depending on the final number of participants and the time allocated for the workshop, all or a selected group of papers will be presented and discussed in the Workshop session.
How to cite the challenge and the systems’ working-notes
We will provide preliminar bibtexts of the systems’ working-notes before the camera ready version. In addition, to cite the eHealth-Kd challenge you can use the following preliminar bibtext:
@article{overview_ehealthkd2021,
author = {Alejandro Piad-Morfis y Suilan Estevez-Velarde y Yoan Gutierrez y Yudivian Almeida-Cruz y Andrés Montoyo y Rafael Muñoz},
title = {Overview of the eHealth Knowledge Discovery Challenge at IberLEF 2021},
journal = {Procesamiento del Lenguaje Natural},
volume = {67},
number = {0},
year = {2021},
keywords = {},
abstract = {This paper summarises the eHealth Knowledge Discovery Challenge hosted at IberLEF 2021. We describe the task, resources, and participating systems, highlighting and discussing the main results achieved in the challenge. We analyse the best performing systems and present recommendations for future research.},
issn = {1989-7553},
url = {http://journal.sepln.org/sepln/ojs/ojs/index.php/pln/article/view/6392},
pages = {233--242}
}
Preliminar IberLEF 2021 proceedings:
@inproceedings{iberlef2021,
author = {Montes, Manuel and
Rosso, Paolo and
Gonzalo, Julio and
Arag{\'{o}}n, Ezra and
Agerri, Rodrigo and
{\'{A}}lvarez-Carmona, Miguel {\'{A}}ngel and
{\'{A}}lvarez Mellado, Elena and
Carrillo-de-Albornoz, Jorge and
Chiruzzo, Luis and
Freitas, Larissa and
G{\'{o}}mez Adorno, Helena and
Guti{\'{e}}rrez, Yoan and
Lima, Salvador and
Montejo-R{\'{a}}ez, Arturo and
Plaza-de-Arco, Flor Miriam and
Taul{\'{e}}, Mariona},
title = {Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2021)},
booktitle = {CEUR Workshop Proceedings},
year = {2021}
}
Please submit your working notes to chairs_eHealth-KD@googlegroups.com and have in mind the deadline.
Organization committee
| Name | Institution | |
|---|---|---|
| Yoan Gutiérrez Vázquez (contact person) | ygutierrez@dlsi.ua.es | University of Alicante, Spain |
| Suilan Estévez Velarde | sestevez@matcom.uh.cu | University of Havana, Cuba |
| Alejandro Piad Morffis | apiad@matcom.uh.cu | University of Havana, Cuba |
| Yudivián Almeida Cruz | yudy@matcom.uh.cu | University of Havana, Cuba |
| Andrés Montoyo Guijarro | montoyo@dlsi.ua.es | University of Alicante, Spain |
| Rafael Muñoz Guillena | rafael@dlsi.ua.es | University of Alicante, Spain |
Discussion group
A Google Group will be set up for this “Health Shared Task” where announcements will be made. Feel free to send your questions and feedback to ehealth-kd@googlegroups.com. General issues and feedback should be posted on our Issues Page in Github.
Follow @eHealthKD on Twitter for up-to-date news, comments and tips about the competition.
Funding
This challenge has been supported by a Carolina Foundation grant in agreement with University of Alicante and University of Havana. Moreover, it has also been partially funded by both aforementioned universities, IUII, Generalitat Valenciana, Spanish Government, Ministerio de Educación, Cultura y Deporte through the projects TECNOLOGÍAS DEL LENGUAJE HUMANO PARA UNA SOCIEDAD INCLUSIVA IGUALITARIA Y ACCESIBLE (PROMETEU/2018/089), LIVING-LANG: MODELADO DEL COMPORTAMIENTO DE ENTIDADES DIGITALES MEDIANTE TECNOLOGIAS DEL LENGUAJE HUMANO(RTI2018-094653-B-C22) and INTEGER:Intelligent Text Generation, GENERACION INTELIGENTE DE TEXTOS (RTI2018-094649-B-I00). In addition, the challenge is also based upon work from COST Actions CA19134 - “Distributed Knowledge Graphs” and CA19142 - “Leading Platform for European Citizens, Industries, Academia and Policymakers in Media Accessibility”.
Scientific publications
Piad-Morffis, A., Gutiérrez, Y., & Muñoz, R. (2019). A corpus to support ehealth knowledge discovery technologies. Journal of biomedical informatics, 94, 103172.
Estevez-Velarde, S., Gutiérrez, Y., Montoyo, A., & Almeida-Cruz, Y. (2019, July). Automl strategy based on grammatical evolution: A case study about knowledge discovery from text. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (pp. 4356-4365).
Piad-Morffis, A., Guitérrez, Y., Estevez-Velarde, S., & Muñoz, R. (2019, June). A general-purpose annotation model for knowledge discovery: Case study in Spanish clinical text. In Proceedings of the 2nd Clinical Natural Language Processing Workshop (pp. 79-88).
Piad-Morffis, A., Gutiérrez, Y., Estévez-Velarde, S., Almeida-Cruz, Y., Montoyo, A., & Munoz, R. (2019). Analysis of eHealth knowledge discovery systems in the TASS 2018 Workshop. Procesamiento del Lenguaje Natural, 62, 13-20.
Estevez-Velarde, S., Gutiérrez, Y., Montoyo, A., & Almeida-Cruz, Y. (2019, October). Optimizing Natural Language Processing Pipelines: Opinion Mining Case Study. In Iberoamerican Congress on Pattern Recognition (pp. 163-173). Springer, Cham.
Piad-Morffis, A., Gutiérrez, Y., Consuegra-Ayala, J. P., Estevez-Velarde, S., Almeida-Cruz, Y., Munoz, R., & Montoyo, A. (2019). Overview of the ehealth knowledge discovery challenge at iberlef 2019. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2019). CEUR Workshop Proceedings, CEUR-WS. org.